Hi everyone! I’m going to tell you how we came up with an idea of a technical solution to optimize the development and QA processes here in Typeable. It all started with a general feeling that we seem to be doing everything quite right, but it can be faster and more efficient when it comes to accepting new tasks, testing, or synchronizing less. All this led us to discussions and experiments which resulted in our open-source solution, which I will describe below and which is now available to you too.
Let’s not rush forward, however, and start from the very beginning to understand thoroughly what I am talking about. Imagine a fairly standard situation: a project with a three-level architecture (database, backend, frontend). There is a development process and a quality control process that would probably consist of several deployment environments:
- Production: the main operating environment, which the users of the system interact with.
- Pre-Production: the environment for testing release candidates (versions that will be used in Production if they pass through all testing stages). This environment is as similar to the Production environment as possible, it integrates with all production services. The purpose of testing in Pre-Production is to gain as much confidence as possible that there will be no problems in production.
- Staging: the environment for rough checking, normally for testing the latest changes and “in progress” versions of the system. This environment uses testing integrations with third-party systems whenever possible. It may differ from Production and is used to verify that new functionality is implemented correctly.
Ideas for improvement
Things are pretty clear with the Pre-production environment: release candidates get there consistently, and the release history is the same as in the Production environment. There are some peculiarities with Staging, however:
- ORGANIZATIONAL. Testing critical parts may postpone deploying new changes, changes may interact in unpredictable ways, tracking errors becomes difficult due to high activity on the server, confusion may arise about what is implemented in which version, it is not always clear which of the deployed changes caused the problem.
- ENVIRONMENT MANAGEMENT COMPLEXITY. Different changes in your system might impose different requirements on the external services they are tested with: one feature might be easy to test with a test service, while another might require the production version of the service to be properly tested. And if you have only one Staging, these settings apply to all implemented features until the next deployment. You have to keep it in mind all the time and alert the employees. The situation generally resembles a multi-threaded application with a single shareable resource: while it is blocked by some data users, all the others are waiting. For example, one QA engineer waits for a payment gateway with production integration to be checked, while the other one checks everything with the testing integration.
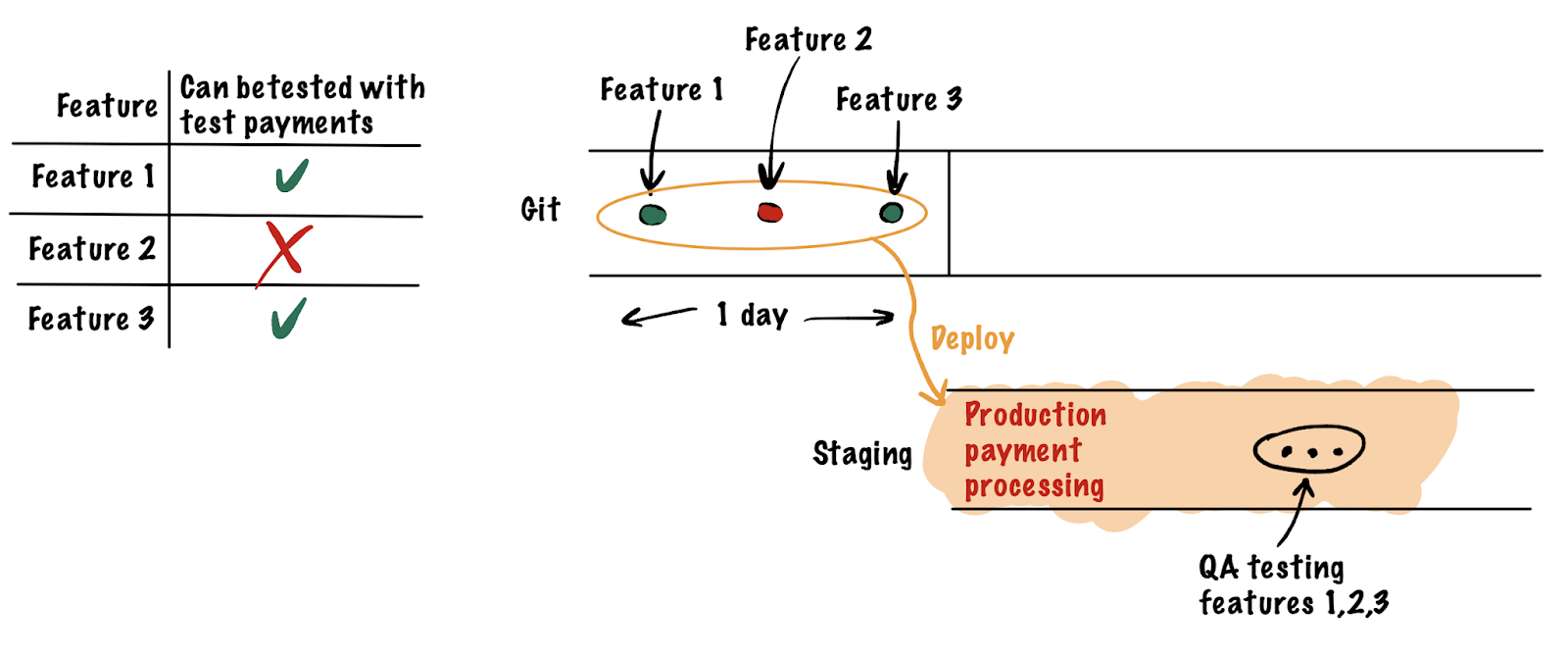
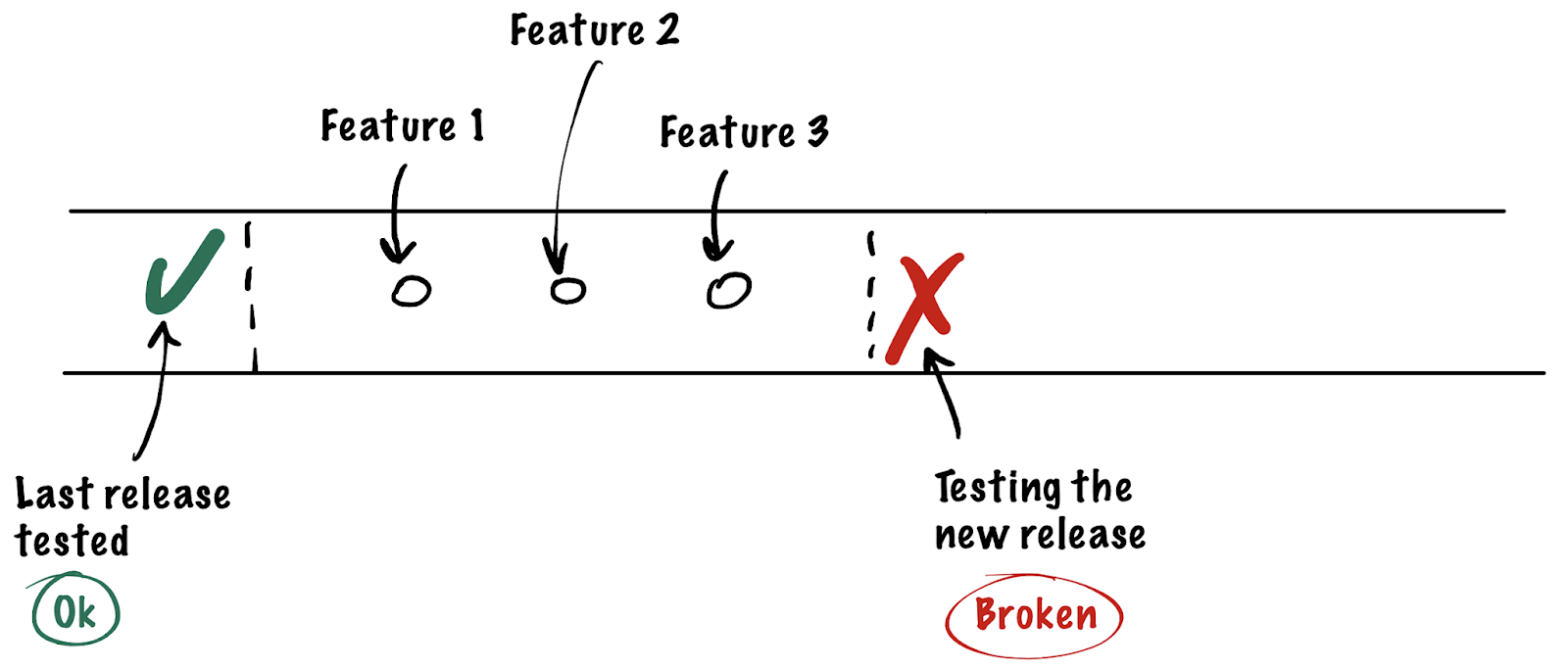
- DEFECTS. A critical defect may block testing of all new changes at once.
- DATABASE SCHEMA CHANGES. It is difficult to control database schema modifications in a Staging environment when it is being actively developed. Constant reverting of the schema can lead to data loss, it is easy to forget to revert when you need to and revert when you don’t. It would be great to have separate isolated databases for every change being tested.
- INCREASED DELIVERY TIME. The combination of the issues listed above sometimes leads to situations when some features become unavailable to testers in time, or the environment settings block you from getting to testing immediately. Because of this, there are delays both on the development and testing sides. Let’s say a defect is detected in some feature, and it is returned to the developer for revision. Meanwhile, they are already busy doing another task. It would be more convenient to get to it earlier before the context is lost. All this leads to increased feature delivery times, which in turn stretches the so-called time-to-production and time-to-market metrics.
Each of these points can be solved on its own one way or another, but the whole thing made me wonder: can we make our lives a bit easier if we move away from the “single staging” concept to a dynamic number of stagings? Just like we have CI checks for each branch in git, we could also get QA check stands for every branch separately. The only thing that stops us is the lack of infrastructure and tools. Roughly speaking what we want is for a separate staging environment with a dedicated URL to be spun up for every feature and for a QA engineer to test the feature on the staging before it is merged (or returned for a fix). Something like this: 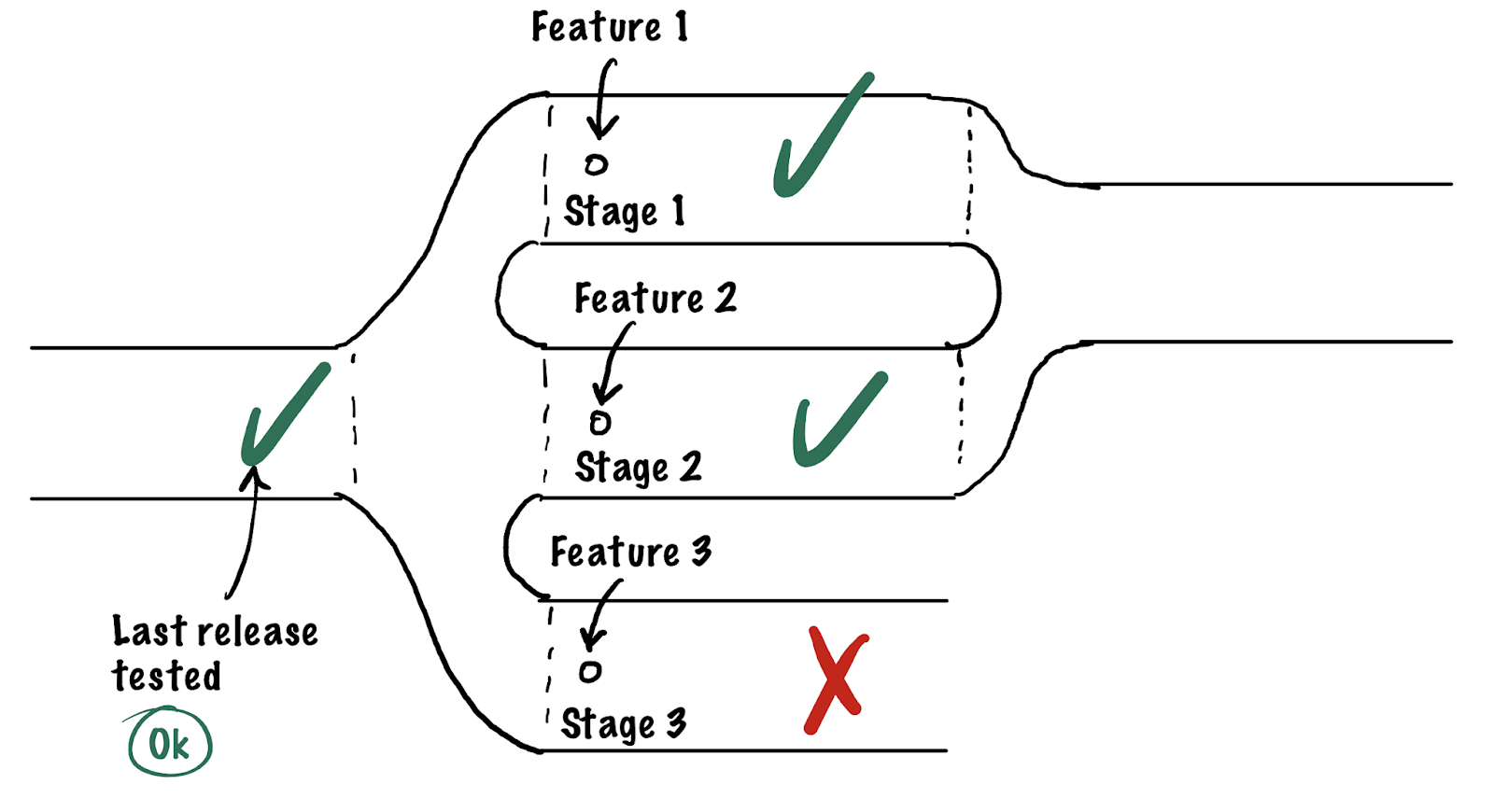
The issues of different environments are worked out naturally with this approach: 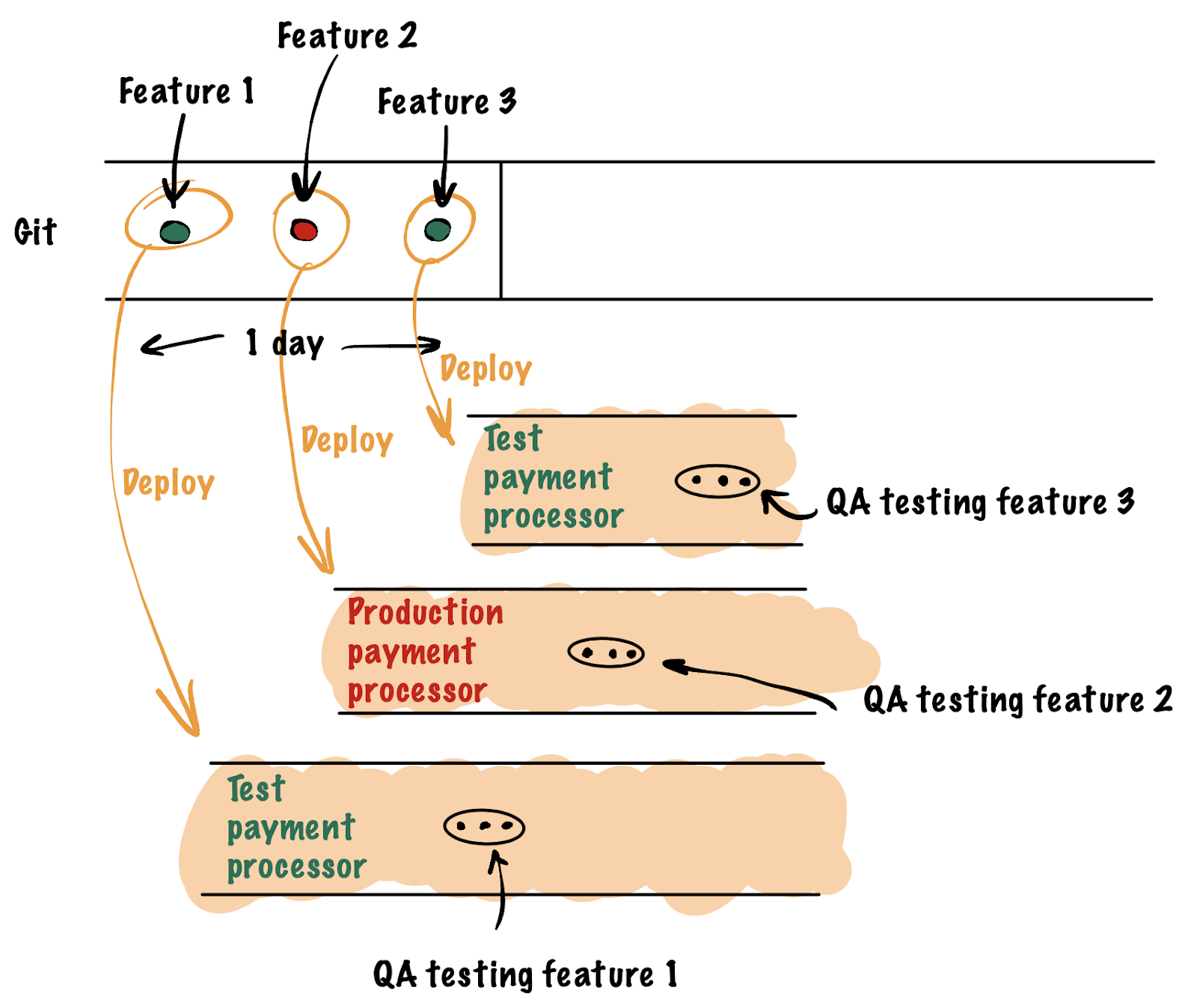
Interesting to note that following the discussion, the opinions in our team were divided between “Let’s try it, it can be improved” and “It seems OK now, I don’t see any huge issues here”, but we will return to that later.
Figuring out the solution
The first thing we tried was a prototype built by our DevOps engineer: a combination of docker-compose (orchestration), rundeck (management), and portainer (introspection), which allowed us to test the overall approach. The prototype had some ergonomics issues:
- Every change required access to both the code and rundeck, which developers had, unlike, for example, QA engineers.
- It was deployed on a single large machine, and it soon became unwieldy. The next logical step required Kubernetes or something similar.
- Portainer gave information about the state of containers, not particular stagings. So this slice of information was semantically awkward, to say the least.
- We had to constantly merge the file with the description of new stagings and delete the old ones.
Even with all its disadvantages and some usage inconveniences, we liked the approach itself, and it started saving the time and effort of the project team. Our hypothesis was proven right and it was time to do the same thing in a more cohesive way. With the goal of optimizing the development process, we revised our requirements and realized what we wanted:
- Use Kubernetes to scale to any number of staging environments and have a standard set of tools for modern DevOps.
- Have a solution that would be easy to integrate into the infrastructure that already uses Kubernetes.
- Create a simple and user-friendly GUI for project managers, product managers, and QA engineers. Even without dealing directly with the code, they should have the tools for introspection and the ability to deploy new stagings. As a result, we won’t bother the DevOps engineers and Developers with every little thing.
- Develop a solution that integrates seamlessly with standard CI/CD pipelines so that it can be used in different projects. We started with a project that uses GitHub Actions for CI.
- Have an orchestration with details that could be flexibly configured by a DevOps engineer.
- Get the ability to make UI customizable enough to hide logs and inner details of the cluster if the project team is concerned about leaking confidential information.
- Full information about the deployments and the action logs should be available to superusers such as DevOps engineers and team leaders.
So we started developing Octopod. The name was a mix of several ideas about K8S, which we used to orchestrate everything in our projects. Many projects in this ecosystem reflect marine imagery, and we imagined a kind of octopus with tentacles orchestrating multiple underwater containers. In addition, Pod is one of the fundamental objects in Kubernetes.
In terms of technical stack, Octopod is based on Haskell, Rust, FRP, compilation to JS, and Nix. But it’s not the part of the story today, so I won’t dwell on this further.
Within the company, we started calling the new model multi-staging. Operating multiple staging environments at the same time is akin to traveling through parallel universes and dimensions in science(or not-so-much-science)-fiction, where the universes are similar to each other, except for one small detail: somewhere different sides have won the war, somewhere there’s been a cultural revolution or a tech breakthrough. The premise may be small, but may lead to dramatic changes! In our processes, this premise was the content of each individual feature branch. 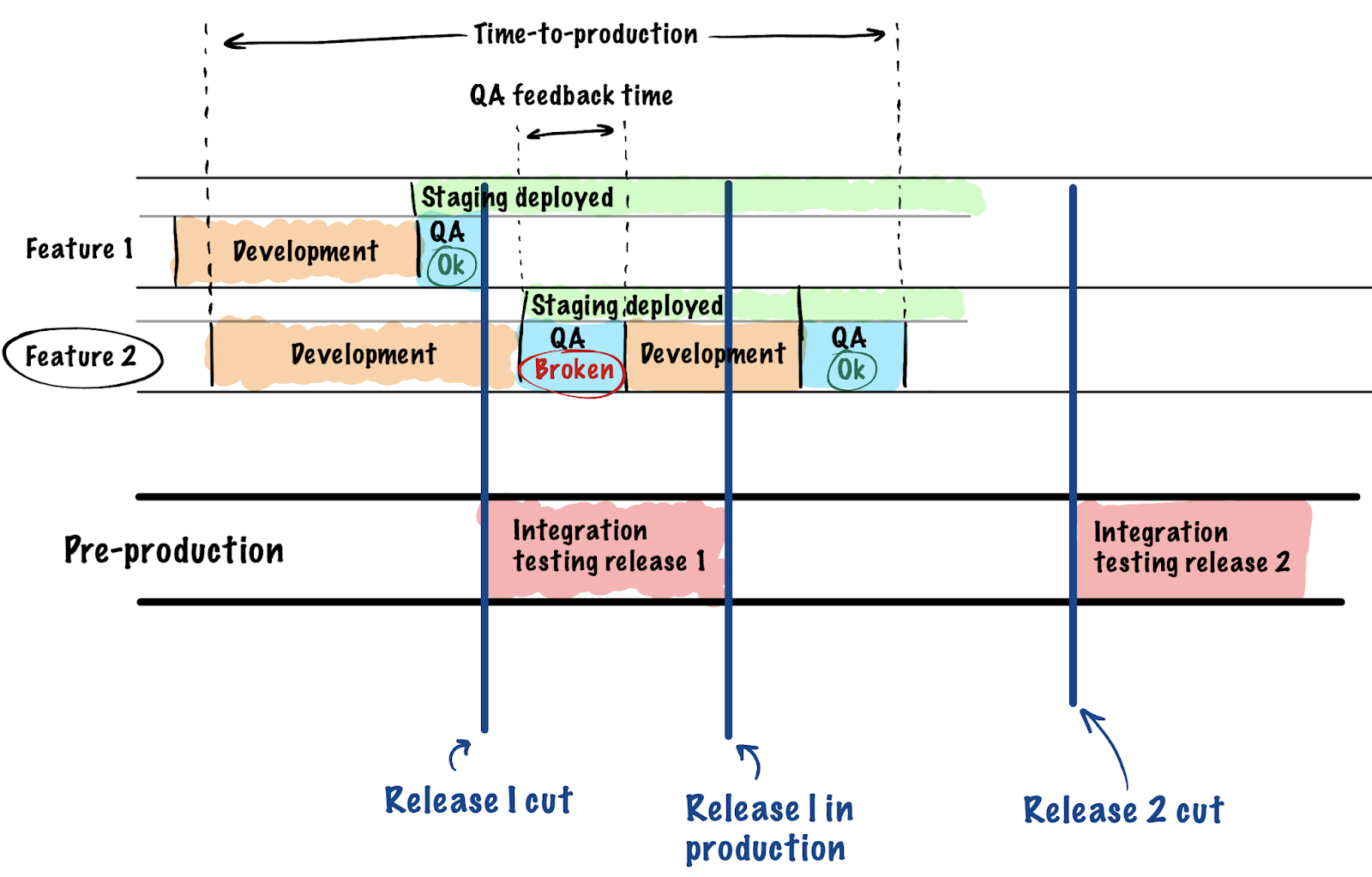
We introduced Octopod in several stages and started with a single project. This process included the adjustment of the project orchestration by DevOps, as well as the reorganization of the testing and communication process by the project manager.
After a number of iterations, some Octopod features were removed or changed beyond recognition. The first version had a page with a deployment log for each environment, but not every team accepted the fact that credentials can flow through these logs to all employees involved in development. As a result, we decided to get rid of this functionality, and then re-implemented it in a different form. Now it is customizable (and hence optional) and implemented through integration with kubernetes dashboard.
Among other things, the new approach requires more computing resources, disks and domain names to support the infrastructure, which raises the question of cost optimization. Combined with DevOps nuances, this will make for another post or even two, so I won’t go on about it here.
In parallel with solving tasks that arise on one project, we began to integrate this solution into another one when we saw interest from its team. This proved that our solution turned out to be quite customizable and flexible for the needs of different projects. At the moment, Octopod has already been widely used in our company for four months.
Takeaways
As a result, this system and processes have been implemented in several projects, and there is interest from one more. Interestingly, even those team members who did not see any problems with the old way of doing things, would not want to switch back to it now. It turned out that for some we solved issues that they didn’t even know about!
The most difficult part, as usual, was the first implementation — we caught most of the technical issues and problems there. Feedback from the users allowed us to better understand what needs to be improved in the first place. In the latest versions, the interface of working in Octopod looks something like this: 
For us, Octopod has become the answer to a procedural question, and I would call the current state an undoubted success: the workflow has clearly become more flexible and convenient. There are still issues not fully resolved: we are dragging the authorization of Octopod itself in the cluster to Atlassian OAuth for several projects, and this process is taking longer than we expected because of bureaucratic and organizational issues. However, it is only a matter of time, as technically the problem has already been solved in the first approximation.
Open-source
We hope that Octopod will be useful not only to us. We look forward to suggestions, pull requests, and information on how you optimize similar processes. If the project proves interesting to the audience, we’ll write about its orchestration and operation details in our company.
The source code with configuration examples and documentation is available in the GitHub repository.