This post is a short case study of using the Alloy modelling language to support software development work.
On software quality and tools
At Typeable we are very conscious about software quality and we are ready to go to some lengths to achieve it. Our current touchpoints for weeding out errors are the following:
- Analysis and specification by dedicated persons
- Applying Haskell type system is to weed out trivial errors
- Usual unit and integration tests
- Continuous integration
- Mandatory code review
- Testing in staging environment by dedicated QA engineers (check out Octopod, our open-source solution for managing multiple deployments)
- Testing in pre-production environment
- Logging and error monitoring during production
Having these many steps helps to keep the code good quality but it also imposes costs. The steps need both time and work.
One way of reducing these costs is by catching your errors early. To give a rough estimate, if the type system catches your error, it will do so within 30 seconds after saving your file. If the error is caught by the CI, it will take up to 30 minutes to produce the error message. And you have to wait another 30 minutes after fixing your mistake for the CI to run again.
The further you go down the chain, the longer these pauses get and the more resources are burned up by mistakes: reaching the QA stage might sometimes take days and then a QA engineer needs to engage with your work. And if the mistake is found here, not only must the QA redo their tests after the mistake is fixed, but the developer needs to pass through all the preceding stages again!
So, how far can we go to catch errors as early as possible? Surprisingly, there is a possibility to greatly improve our chances of catching errors even before writing a single line of code!
Enter Alloy
This is where Alloy comes in. Alloy is a splendidly simple and ergonomic modelling tool that allows you to build testable specifications for the system you’re about to code.
What Alloy does in practice is that it offers a simple language for building an abstract model of your idea or specification. And when the model is built, Alloy will do its best to show you all the disturbing things your specification will permit. It can also do model checking for any properties you think are important.
Let’s pick up an example! Recently we had a nuisance issue with the following bit of code:
newAuthCode
:: (MonadWhatever m)
=> DB.Client
-> DB.SessionId
-> m DB.AuthorizationCode
newAuthCode clid sid = do
let codeData = mkAuthCodeFor clid sid
void $ DB.deleteAllCodes clid sid
void $ DB.insertAuthCode codeData
return codeThis was in an HTTP endpoint and the code was supposed to go in to the database, delete all existing authorization codes for the user and write a new one in. Mostly, the code did just that. But it was also slowly filling our logs with “uniqueness constraint violation” messages.
How come?
Modelling
The above problem makes a good example problem for Alloy. Let’s try to figure it out by building a model! To model our specific problem case, we would usually start by describing our idea of newAuthCode operations to Alloy. That is, one would first build a model of the operations, then complement it by building a model of the database and linking the behaviour of the database to the operations.
However, in this case, it turns out that just formalizing our notion of what our operations could look like is enough to spot the problem.
The process described by our code snippet has two interesting parts. It does a delete at some point in time and then it inserts a new token at some other time. Here is one Alloy model for specifying this behaviour:
open util/time // Import premade Time objects
sig Operation // There are operations...
{ delete : Time // ...that do a delete on some time instance
, insert : Time // ...and an insert at some other time
}
{ lt[delete,insert] // The deletes happen before the inserts
lt[first,delete] // And, for technical reasons, nothing happens
// during the first time instance.
}
run {some Operation} for 4 // Show me a random instance with up to
// 4 OperationsThe above model describes a system of abstract objects and relationships between those objects. Running the model will then produce a random universe containing some Operations that are laid out according to the given rules.
If you want to follow along, download Alloy and copy-paste the above snippet into it. Then press ‘execute’ and ‘show’ to get the following view of the model:
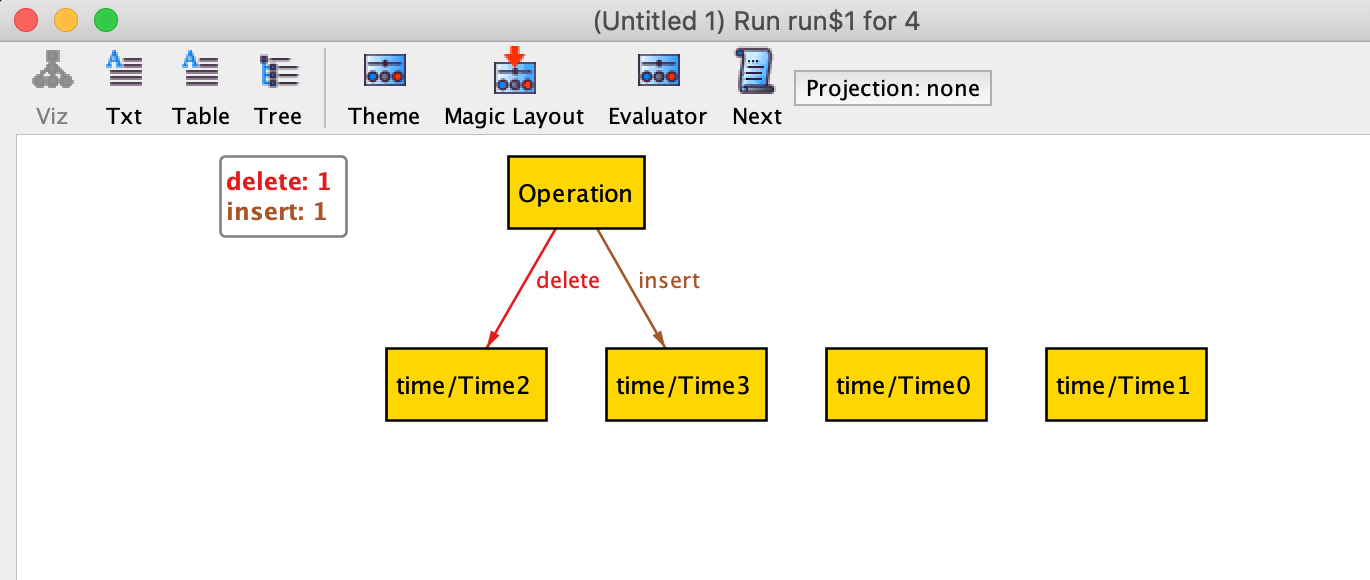
To get Alloy to show you more models, you can press ‘next’.
Here is one of those random instances laid out as a relationship table (you need to press ‘next’ a few times and choose ‘Table’ view):
┌──────────────┬──────┬──────┐
│this/Operation│delete│insert│
├──────────────┼──────┼──────┤
│Operation⁰ │Time¹ │Time³ │ ← Operation⁰ does a delete at Time¹ and
├──────────────┼──────┼──────┤ insert at Time³
│Operation¹ │Time² │Time³ │ ← Operation¹ does a delete at Time² and
└──────────────┴──────┴──────┘ insert at Time³
↑
Oh dear!Usually, at this point, we’d start modelling database tables and semantics of the operations, but it turns out that Alloy has already managed to make it obvious why our logs have constraint violations!
Our handler gets called concurrently and the operation sequences overlap badly: there are two operations and they both do a delete around the same time and then they both do an insert at the same time. Also, since this is not a read, the postgresql default isolation level will not do anything to stop this from happening.
I found the bug!
Let’s fix it!
When I first investigated the issue, I wrote essentially the following fix for it.
code <- run $ do
handleJust constraintViolation
(launchPG $ selectCodeForSession clid scope sid
(launchPG . pgWithTransaction $ newAuthCode clid scope sid)My idea was that if the operations did overlap and the insertion did fail, we then know that a new auth code has just been inserted. So, we can just do a select and return this existing code, since it can’t be more than a moment old.
Will it work now?
Let’s build a quick Alloy model for our fix to see if we got it correct:
open util/time // Import Time
sig Token {} // There are objects called tokens
one sig DBState // There is a database with some tokens
{userToken : Token lone -> Time}
// There are one or zero tokens at any given time in the DB
// (because database constraints don't allow for more than one)
sig Operation {
delete : Time
, insert : Time
, select : Time // Our operations can now also do a select
}
{
lt[first,delete] // Nothing happens on first time instance for
// technical reasons
lt[delete,insert] // delete happens first
lte[insert,select] // insert can happen after, or at the same time
// as delete
no userToken.(insert.prev) // If the insert works (ie. table is
=> insert = select // empty when we try, we get the value
// at the time of the insert (ie. we have
// 'INSERT RETURNING' statement)
// Otherwise, we execute the exception handler and
// the select may happen a bit later.
}Up to this far the model follows the previous model quite closely. We added a DBState for modelling the table that stores our tokens and our operations now do a select, which must occur similarly as it occurs in our code. That is, if the table is empty, we select the token while inserting it and if the table is full, we select it later in the exception handler.
Then we get to the interesting part of the model, which is specifying the interactions between the operations and the database state. Luckily, for our model this is rather simple:
fact Trace { // The trace fact describes how our system behaves
all t : Time - first | { // at all time steps, except the first:
some delete.t => no userToken.t // If there is a delete, the table is empty
some insert.t => some userToken.t // If there is an insert, table is not empty
no delete.t and no insert.t // If there are no inserts and no deletes,
=> userToken.t = userToken.(t.prev) // the table does not change
}
}That is, we describe how the database changes state regarding which events take place.
Running this model creates many instances, but unlike before, just browsing through them is not enough to find anything obviously wrong. But we can ask Alloy to check some facts for us. This point can take a little thinking, but it seems that our fix could work if all the selects work.
Let’s state that as an assertion and ask Alloy to check if it holds.
assert selectIsGood { // This is what we want Alloy to check
all s : Operation.select | // For all times when there is a select
some userToken.s // there is also a token in the database.
}
check selectIsGood for 6 // Check that selectIsGood is always true.And, unfortunately, running this check gives us the following counterexample:
┌────────┬────────────┐
│DBState │userToken │
├────────┼──────┬─────┤
│DBState⁰│Token²│Time³│
│ │ ├─────┤ ← Token² is in the DB at Time³ and Time⁵
│ │ │Time⁵│
│ ├──────┼─────┤
│ │Token³│Time²│ ← Token³ is in the DB at Time².
└────────┴──────┴─────┘
↑
There are tokens in the table
only on Time², Time³ and Time⁵
Notably, there are no tokens at
Time⁴!
┌──────────────┬──────┬──────┬──────┐
│Operation │delete│insert│select│
├──────────────┼──────┼──────┼──────┤
│Operation⁰ │ TIME⁴│ Time⁵│ Time⁵│
├──────────────┼──────┼──────┼──────┤
│Operation¹ │ Time¹│ Time³│ TIME⁴│ ← The table is empty at Time⁴ and
├──────────────┼──────┼──────┼──────┤ the select fails for Operation¹!
│Operation² │ Time¹│ Time²│ Time²│
└──────────────┴──────┴──────┴──────┘
↑ ↑ ↑
These are the times when the
respective actions take placeThis time the counterexample is more complex. For our fix to fail, there must be three operations that occur concurrently. First, two of these operations do a delete and clear the database. Then, one of these two operations inserts a new token to the database, while the other fails to insert since there is a token in the table already. The operation which fails begins executing the exception handler, but before it manages to finish, a third operation comes in and clears the table again, leaving the select statement in the exception handler with nothing to select.
So, the proposed fix, which was type-checked, tested, CI’d, and peer-reviewed is actually faulty!
Concurrency is hard.
My Takeaways
It took me roughly half an hour to write the above Alloy models. In contrast, it originally took probably twice as much time to understand the issue and fix it. Then I also waited half an hour for the CI and my colleagues took some time to review my work.
Since the fix doesn’t even work, I can say that it certainly took longer to fix the issue than it would’ve if I’d stopped to model the issue when I found it. But, regrettably, I didn’t touch Alloy at all since the problem was ‘simple’.
This seems to be the difficult part with the tools like this. When do you pick them up? Certainly not for every problem, but perhaps more often than I do currently.
Where to get Alloy?
If you got piqued, here are few links to get started with Alloy:
- https://alloytools.org/ <- Get it from here
- https://alloy.readthedocs.io/en/latest/ <- These are way better than official docs
- https://mitpress.mit.edu/books/software-abstractions <- An easy to read book about Alloy. This book will give you most of the basic patterns to get you started.
- https://alloytools.org/citations/case-studies.html <- Alloy authors keep a list of uses for their tool here. It is quite complete and has a large variety of use cases.
PS. The right fix for this problem is to use serializable transactions and not to muck with concurrency one bit.